图一:对主题可解释性的几种计算测度。
LDA主题模型(Latent Dirichlet Allocation Topic Model,LDA-TM),因其远读和超书架功能能够以主题词聚类的方式直观呈现单个文本及海量文本库所隐含的语义结构,被越来越多地用于辅助人文解释和论证,目前已涵盖新闻传播、文学、史学、文化学、诗歌、中国古代典籍和哲学等各个领域。例如,西安交通大学与美国印第安纳大学合作开发的汉典主题模型,就是在古汉语文本语料库基础上建立的LDA主题模型。
然而,人工智能和机器学习只是呈现出算法得出的词汇聚类,究竟每个类(即主题)有什么意义,至少目前来说还需要由人来解释。形象地说,由人结合人文领域专业知识给出解释,就是给主题贴标签。而人类使用者只能通过检视一个主题中极少量的最高概率核心词作判断,这里就存在如下两个问题。一是全部词项在每个主题中是全概率分布,仅依靠前15或20个最高权重词来判断一个主题的意义,实际上不得不放弃绝大多数词的主题权重,结果是否会存在一定局限性?我们实验室的另一项工作正在对此进行探究。二是基于人文语料库训练的LDA主题模型需要有良好的质量,这是解释和论证的基础,那么,可否建立评估模型质量的计算方法?本项工作就是从主题模型的解释学视角首次进行这样的尝试。
作为机器学习辅助人文研究的一种新工具,LDA主题模型具有良好的质量,就意味着训练出的词语集簇(主题)具有可解释性,使人们容易判断和解释其意义。虽然对于如“汉典”这类基于人文语料库的主题模型来说,并不存在对主题内容的统一标准解释,但当评估者实际面对主题时,不同主题的解释难度的确存在较大差异。因此,我们将模型的可解释性与人工得出判断的难易程度相关联,即人工作出判断的难度越低,该模型的可解释性就越好。因为背景知识水平、目标、动机及判断过程中出现的各种其他心理因素的差异,人工判断的结果往往差异较大。而且,进行人工判断还需找到并组织合适的人员来参与评估模型,这种方式的效率较为低下。我们的目标是参照人工评估结果,尝试建立可靠的计算方法去评估模型的可解释性,以替代效率低下的人工方法。
以人工评估作为计算评估的参照
我们先通过问卷调查方式获取模型主题质量的人工评估结果。我们从国内一所重点大学邀请了150名来自不同专业的学生并将其进行分组。通过系统抽样的方法从汉典主题模型中抽取75个主题,并将这75个主题进行分组。将每个主题的最高权重词的前15个显示给学生(具体形式如,Topic 25:气,服,热,治,病,水,寒,血,黄,汤,脉,阳,痛,药,阴)。每个主题分别由50个学生通过阅读前15个最具代表性的词语来进行评估。我们要求学生用2—3个词概括每一主题的意思,并给出解释难易程度的评估分值。最终我们收集到3750条数据。
在评估过程中,因评估者心理因素和知识背景等存在多重差异,很难找到一个标准的人工评估结果。在此次研究中,所有评估者都是对中国传统文化有一定常识的大学生,他们的知识背景保持大致相同水平。这样,以平均分数代表人工评估结果是合理的(如果评估者中有一些关于中国传统文化的专家,那么评估结果会存在一个等级结构,我们则需要对专家评估结果和学生评估结果给予不同的权重)。最终,每一主题都有50个由评估者给出的分值,我们取这50个评估分值的平均值作为该主题的人工评估结果。
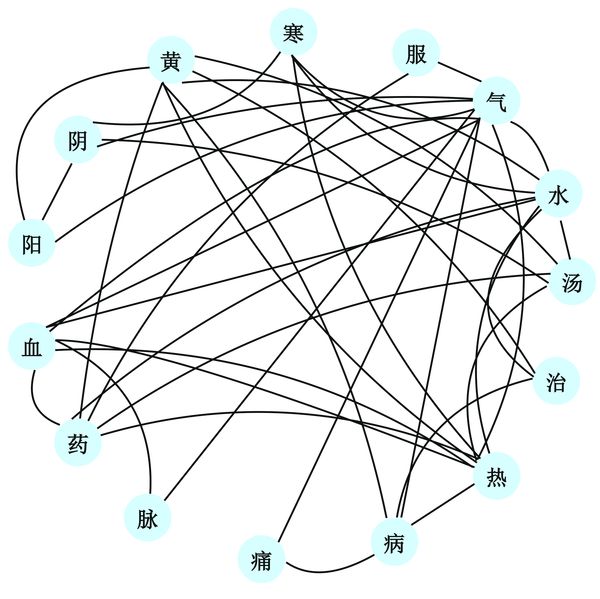
图二:截取Topic 25前15个核心字之间的组合关系(K=40),一组核心字总是集中于一特定区域,故我们称这一组为“主题”。
探索可能的计算方法
许多因素都有可能影响人对主题的理解和解释。针对汉典主题模型的解释,我们提出两个假设。假设一:“语义相似性”假设。前15个词项间的语义相似性会影响评估者对主题进行概括和解释的难易程度,词项之间语义相似性更高,评估者就更容易对这一组词项所表达的意义进行概括和解释。假设二:“词语熟悉度”假设。评估者对一组词的熟悉程度会影响其进行概括和解释的难易程度,对词语越熟悉,就越容易对该主题所表达的意义进行概括和解释。
假设一对应的计算方法是测量词距,我们采用开源的“中文同义词词典计划”(https://github.com/huyingxi/Synonyms)来测度主题词之间的同义性。该词典使用Word2vec(https://radimrehurek.com/gensim/models/word2vec.html)这种人工神经网络方法,在具有丰富语境信息的大数据中训练出高质量的同义词模型。其原理是将语义表达映射到向量表征,这样,所有词汇都被映射到一个高维度的向量空间中,词与词之间的相似性就可根据高维空间中的向量间距离来测量。
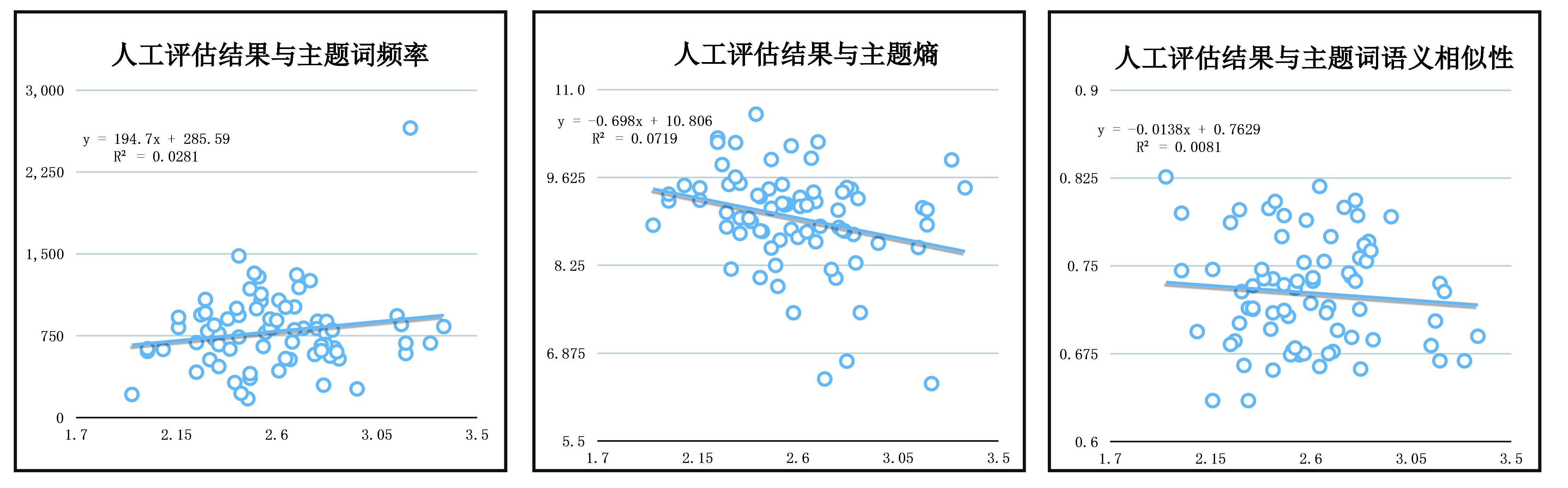
经过下载维基汉字语料库、繁简体转换、解霸分词、训练词向量4个步骤,我们计算得到每个主题中词与词之间同义性的量度(数值范围0—1,越趋近于1,词义越相似),再与之前得到的人工评估结果进行比较(数值范围1—5,数值越大,主题越易解释)。我们假定,两个值应该呈现正相关性,然而计算结果显示出一种极弱的负相关性(如图一左所示)。
假设二对应于计算主题词的熟悉度与主题解释性之间的关系,我们考虑从测量主题熵和主题词词频两个方面来进行。主题的“香农熵”就是测量该主题在语料库文档中的分布。主题熵值越高,该主题就越可能成为许多文档的高权重主题。按照我们的假定,主题熵与主题的解释性之间应呈现出一种负相关性,因为主题熵越低,主题出现在更少的文档中,意义更明确。数据结果与我们假定一致,但显示出的相关性很弱(如图一中所示)。
关于词频,词频越高,意味着人们对该词越熟悉。因此,由高频词主导的主题意义就更易解释。虽然高频词往往是如“礼”“理”“道”“气”这类具有多重语义蕴涵的中国哲学核心词,但多重语义并不降低主题的可解释性,因为人们识别主题意义时,往往根据词与词的相关性(即语境)作判断。而主题模型的主题恰恰可以聚类析别出一个多义词的不同语境。比如,“气”分别有中医理论的气、道家宇宙论的气、理学工夫论的气等语境。因此,我们假定主题词频应与可解释性呈正相关。数据结果与我们的假定一致,但显示的正相关性也很弱(如图一右所示)。
另外,在计算词频时,考虑到汉典的古汉语语境,以及人工评估主体处于当下认知文化背景,我们使用的是汉字词频表而非汉语词词频表,而且是现代汉字词频表而非古代汉字词频表。
讨论及反思
在主题模型的解释学探究中,一个重要而有趣的认知问题是,人们究竟是如何概括得出主题模型中一个个词群的意义的?我们对人工评估出的最易和最难解释的各自TOP10主题进行仔细考察,发现除上述考察的词语熟悉度因素外,评估者对主题可解释性的判断还可能基于是否能将字组成词。由此,我们将各个主题前15个单字词进行排列组合,计算其能组成的双字词、三字词和四字词的数量总和,再通过对照现代汉语词典和词频列表检查这些组合,从而得到以此方式组成的有意义词语的数量(如图二所示)。数据分析显示,可形成有意义词语的数量(即该主题的可组合性)与可解释性呈正相关,与我们的预测一致。
上述我们的初步分析得出,主题词的语义相似性、主题熵和主题词频率是评估主题模型质量的三种可能的计算方法。但是,当评估者在评估主题的可解释性时,相比词与词之间的语义相似度,人对词的熟悉度对于主题可解释性的影响可能更为重要,根据熟悉度设计计算方法可能更有意义。同时,考察人们如何在汉典主题模型背景下解释一组主题词,并发现主题中单字词之间的关系,也是一个值得进一步探究的问题。考虑到前面测量主题词距与可解释性之间得到的弱相关结果,将词距测量与可组合性结合,可作为进一步考察的思路。
(作者单位:西安交通大学计算哲学实验室;南京大学哲学系;美国匹兹堡大学科学史与科学哲学系)



